
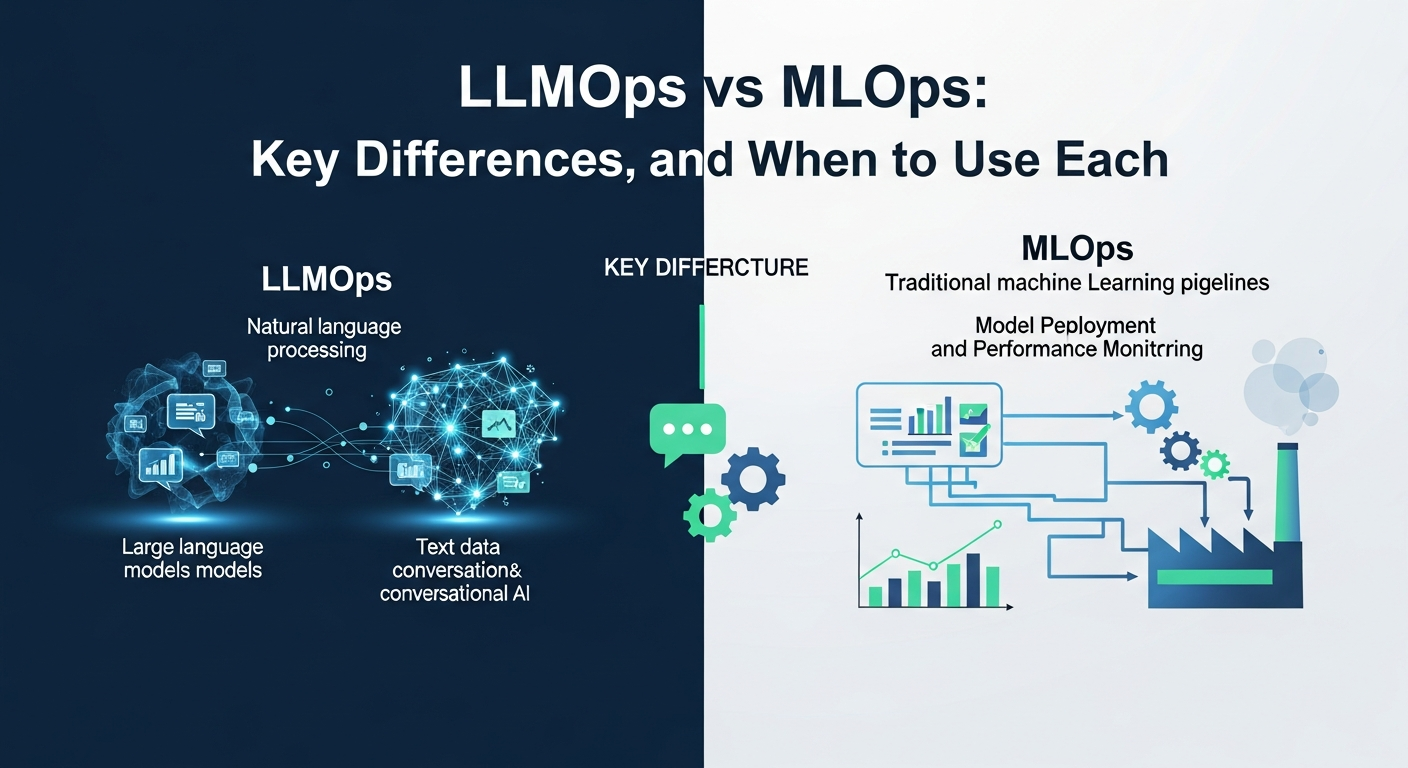
LLMOps vs MLOps: Key Differences, Architecture, and When to Use Each
Introduction/Overview
The Rapid Evolution of AI and the Need for Robust Operations
The artificial intelligence landscape is experiencing an unprecedented period of growth and transformation. What began with the gradual integration of traditional machine learning models into business processes has recently exploded with the advent of generative AI and, most notably, large language models (LLMs). These powerful models have captivated the world with their ability to understand, generate, and manipulate human language, promising to revolutionize industries from content creation to customer service.
However, the journey from a groundbreaking AI model in research to a reliable, scalable, and ethical application in production is fraught with complexity. This is where the discipline of operationalizing AI comes into play. For years, the industry has relied on MLOps – a robust set of practices, tools, and principles designed to streamline the entire machine learning lifecycle. MLOps ensures that traditional ML models are developed, deployed, monitored, and maintained effectively and efficiently.
From MLOps to LLMOps: Addressing New Paradigms
While MLOps has proven indispensable for traditional machine learning, the unique characteristics and immense scale of large language models introduce a fresh set of challenges that extend beyond the scope of conventional MLOps frameworks. LLMs require specialized approaches for everything from prompt engineering and fine-tuning to grounding, responsible AI considerations, and dynamic monitoring of emergent behaviors. These distinct requirements necessitate a new, dedicated operational framework: LLMOps.
Understanding the nuances between these two crucial paradigms is no longer just beneficial, but essential for any organization looking to harness the full power of AI. Whether you're a Machine Learning Engineer, Data Scientist, AI Architect, or an IT decision-maker, distinguishing between MLOps and LLMOps is critical for strategic planning and successful deployment.
What You'll Learn: Navigating the LLMOps vs. MLOps Divide
This article will provide a comprehensive comparative analysis of LLMOps and MLOps, equipping you with the knowledge to make informed decisions. We will delve into their fundamental distinctions, explore their respective architectural components, and offer practical guidance on when and where to strategically apply each framework. By the end, you'll have a clear understanding of how to optimize your AI operations to support both traditional ML models and the latest generation of generative AI, ensuring your projects are not just innovative, but also production-ready and sustainable.
Main Content
Understanding MLOps: Operationalizing Machine Learning
At its core, MLOps definition refers to a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. It bridges the gap between traditional software development (DevOps) and machine learning, ensuring that the entire machine learning lifecycle — from data preparation and model training to deployment and monitoring — is streamlined, automated, and governed. The primary objectives of MLOps include achieving high levels of reproducibility, scalability, and automation in ML workflows.
The typical machine learning lifecycle, as addressed by MLOps, encompasses several critical stages:
- Data Preparation & Feature Engineering: Collecting, cleaning, transforming, and engineering features from raw data.
- Model Development & Training: Experimenting with different algorithms, training models, and tuning hyperparameters.
- Model Deployment: Taking a trained model and integrating it into an application or service for inference, often via APIs or batch processing. This is a crucial step for bringing ML to end-users.
- Model Monitoring & Management: Continuously observing the model's performance in production, detecting data drift, concept drift, and ensuring model integrity. This feedback loop is vital for sustained performance.
- Model Retraining & Updates: Based on monitoring insights, models are often retrained with new data or updated with better algorithms to maintain relevance and accuracy.
MLOps ensures that these stages are not isolated but rather form a cohesive, iterative pipeline, allowing for rapid iteration and robust management of AI systems.
The Foundational Pillars of MLOps
To achieve its goals, MLOps relies on several key pillars that collectively define its operational framework:
- Data & Experiment Management: This involves versioning datasets, tracking experiments, managing hyperparameters, and storing model artifacts. It ensures reproducibility and helps in comparing different model iterations.
- CI/CD for ML (Continuous Integration/Continuous Delivery): Adapting DevOps principles to ML, this pillar automates the build, test, and deployment of ML code and models. It includes automated data validation, model testing, and deployment to production environments.
- Model Registry: A centralized repository for storing, versioning, and managing trained models. It facilitates tracking model metadata, approval workflows, and ensures only validated models are deployed.
- Monitoring & Governance: Beyond just technical performance, this pillar focuses on continuous model monitoring for data drift, concept drift, and prediction integrity. It also encompasses robust AI model governance, ensuring compliance with ethical guidelines, regulatory requirements, and organizational policies throughout the model's operational lifespan.
Introducing LLMOps: MLOps Specialized for Large Language Models
While MLOps provides a solid foundation, the advent of Large Language Models (LLMs) has introduced a new paradigm, necessitating a specialized approach: LLMOps definition. LLMOps can be understood as an extension and specialization of MLOps, specifically tailored to address the unique complexities and operational requirements of deploying, managing, and scaling LLMs in production environments. It adopts MLOps principles but adapts them to the distinctive characteristics of LLMs, such as their massive scale, emergent behaviors, and interaction patterns.
The ‘why’ behind LLMOps is rooted in the significant differences LLMs present compared to traditional ML models. These differences span the entire LLM lifecycle and introduce unique challenges:
- Prompt Engineering & Context Management: Unlike traditional models with fixed inputs, LLMs heavily rely on prompt engineering – crafting effective prompts to guide their behavior. Managing prompt versions, context windows, and retrieval-augmented generation (RAG) systems becomes a core operational task.
- Model Alignment & Safety: Ensuring LLMs generate helpful, harmless, and honest outputs is paramount. This involves continuous evaluation for bias, toxicity, and adherence to safety guidelines, often requiring human-in-the-loop feedback mechanisms.
- Evaluation of Unstructured Output: Traditional metrics often fall short for LLMs. Evaluating the quality, relevance, and factual accuracy of free-form, unstructured text outputs requires novel qualitative and quantitative approaches, including human preference judgments and advanced similarity metrics.
- Cost Optimization: LLMs are computationally intensive. Managing inference costs, optimizing model serving, and fine-tuning strategies for efficiency are critical operational considerations.
- Dynamic Integration & Observability: LLMs are often part of complex agentic systems or integrated into larger applications, demanding advanced observability tools to track interactions, token usage, and latency across multiple components.
LLMOps, therefore, augments MLOps with specialized tools and processes to navigate these intricacies, ensuring reliable, ethical, and performant LLM applications.
Supporting Content
MLOps in Action: Traditional Machine Learning at Scale
MLOps serves as the backbone for deploying, monitoring, and maintaining traditional machine learning models in production, ensuring they deliver consistent value. Its principles are crucial for managing the entire lifecycle of models, from experimentation to continuous deployment, particularly in domains requiring robust predictive analytics.
One prominent example of MLOps use cases is in credit fraud detection. Financial institutions leverage sophisticated ML models to identify suspicious transactions in real-time. Without MLOps, managing these models would be a significant challenge. MLOps provides automated pipelines for data ingestion, model training (often on new, labeled fraud data), validation, and deployment. It ensures that when new fraud patterns emerge, models can be rapidly retrained and updated in production without manual intervention, maintaining high accuracy and minimizing false positives. Furthermore, MLOps platforms offer robust monitoring capabilities to track model performance drift, data drift, and fairness metrics, ensuring the system remains effective and compliant.
Another critical application is in predictive maintenance for industrial equipment. Companies use MLOps to deploy models that predict machinery failures before they occur, optimizing maintenance schedules and preventing costly downtime. Here, MLOps handles diverse data streams from IoT sensors, orchestrates complex feature engineering, manages model versions, and facilitates A/B testing of new algorithms. The emphasis is on the continuous improvement of these models, where MLOps ensures that as more operational data becomes available, models are regularly updated and redeployed, constantly refining their predictive accuracy and delivering tangible operational efficiencies. This guarantees that models are always running optimally in dynamic environments.
LLMOps Unleashed: Mastering Generative AI Applications
While MLOps handles structured and semi-structured ML tasks, Large Language Models introduce a distinct set of complexities that necessitate a specialized approach: LLMOps. This framework is vital for managing the unique lifecycle challenges of generative AI, particularly in scenarios where models are constantly evolving and interacting with users in dynamic ways. The adoption of LLMOps is becoming a cornerstone for successful enterprise AI initiatives.
One prime example of LLMOps applications is the deployment of advanced conversational AI systems or enterprise-grade chatbots. Unlike traditional rule-based or intent-driven chatbots, LLM-powered systems handle nuanced, open-ended conversations. LLMOps steps in to manage crucial aspects like prompt engineering iterations, ensuring consistent and safe outputs. It facilitates A/B testing of different prompt strategies, monitors for hallucinations or undesirable biases, and orchestrates fine-tuning pipelines using proprietary data. The evaluation of these models is particularly challenging, requiring human-in-the-loop feedback and sophisticated metrics beyond simple accuracy, making LLMOps indispensable for their iterative refinement and safe deployment.
Another significant area is content generation at scale and intelligent search with RAG systems. Imagine a platform that automatically generates marketing copy, summarizes documents, or enhances search results by retrieving and synthesizing information from vast knowledge bases (RAG systems). LLMOps is critical here for managing the lifecycle of these intricate systems. This includes versioning base models and their fine-tuned variants, orchestrating the integration with external data retrieval components, monitoring the relevance and factual accuracy of generated content, and ensuring cost-effectiveness of API calls. LLMOps ensures these systems are robust, scalable, and adaptable to new information and evolving user needs, providing a comprehensive framework for managing the dynamic and evolving nature of large language models in production.
Advanced Content
Moving beyond the conceptual distinctions, a true understanding of LLMOps and MLOps hinges on dissecting their respective architectural blueprints. While both aim to streamline the machine learning lifecycle, the fundamental differences in model types—traditional statistical/discriminative models versus large language models—necessitate divergent architectural components and specialized considerations. This section provides a deep dive into the technical underpinnings of each, offering a clear blueprint for practitioners.
Deconstructing MLOps Architecture
The bedrock of operationalizing conventional machine learning models lies in a robust MLOps architecture designed for reproducibility, scalability, and continuous improvement. It encompasses a suite of interconnected components that manage the entire lifecycle from data ingestion to model deployment and monitoring.
- Data Pipelines (ETL/ELT): These are fundamental for ingesting, transforming, and loading raw data into a usable format. Robust data pipelines ensure data quality, consistency, and availability for training.
- Feature Stores: A centralized repository for managing, serving, and documenting features. Feature stores are critical for ensuring feature consistency between training and inference, preventing data leakage, and promoting reusability across multiple models.
- Model Training Infrastructure: This involves scalable compute resources (GPUs, TPUs, distributed clusters) and orchestration tools for efficient model training, hyperparameter tuning, and experimentation.
- Model Registry: A central hub for versioning, storing, and managing trained models. The model registry tracks model metadata, lineage, performance metrics, and approval statuses, facilitating governance and deployment.
- CI/CD Pipelines for ML: Extending traditional software CI/CD, these pipelines automate the build, test, and deployment of ML code, data schema changes, and model artifacts, ensuring continuous integration and continuous delivery.
- Model Serving (Online/Batch Inference): Infrastructure for deploying models to production, providing low-latency predictions via REST APIs (online inference) or processing large datasets asynchronously (batch inference).
- Monitoring & Alerting: Systems to continuously track model performance (e.g., accuracy, latency), detect data drift, concept drift, and system health, with automated alerts for anomalies.
Specific architectural considerations within MLOps further solidify its reliability:
- Data Versioning: Tracking changes to datasets and features, crucial for debugging and reproducibility.
- Experiment Tracking: Logging all aspects of model training runs—parameters, metrics, code versions—to compare and reproduce experiments.
- Infrastructure as Code (IaC): Managing and provisioning infrastructure through code, ensuring consistent and repeatable environments.
- Reproducibility: The ability to recreate a model's exact behavior and results at any point in time, vital for auditing and debugging.
The Evolving Landscape of LLMOps Architecture
While borrowing foundational elements from MLOps, the LLMOps architecture introduces specialized components to address the unique challenges of large language models, including their scale, generative nature, and inherent complexities.
- Prompt Management Systems: Critical for versioning, templating, and optimizing prompts—the new "input data" for LLMs. These systems enable A/B testing prompts and ensure consistent model behavior.
- Fine-tuning Pipelines: Dedicated pipelines for adapting pre-trained LLMs to specific tasks or domains using smaller, task-specific datasets. This includes data preparation, distributed training, and model checkpointing.
- Vector Databases (for RAG): Essential for Retrieval Augmented Generation (RAG) patterns, vector databases store dense vector embeddings of documents, enabling semantic search and providing LLMs with external, up-to-date knowledge.
- Guardrails & Safety Layers: Implementing mechanisms to filter inappropriate content, enforce ethical guidelines, prevent prompt injection attacks, and ensure responsible AI usage. These LLM guardrails are paramount for safe deployment.
- LLM Evaluation Frameworks: Beyond traditional metrics, these involve human-in-the-loop evaluation, automated metrics for generation quality (e.g., perplexity, ROUGE, BLEU), and RAG-specific metrics (e.g., RAGAS) to assess factuality and relevance.
- Human-in-the-Loop (HITL) Feedback Mechanisms: Incorporating human review and feedback to continuously improve LLM responses, often used in conjunction with Reinforcement Learning from Human Feedback (RLHF).
- Observability for LLMs: Advanced monitoring beyond basic latency and throughput, focusing on token usage, prompt quality, generation coherence, safety violations, and tracing individual prompt-response interactions.
Key LLMOps architectural considerations:
- Cost Optimization: Managing the substantial inference costs of large models, including techniques like quantization, knowledge distillation, and efficient serving strategies.
- Latency Management: Optimizing response times for real-time applications, often involving GPU acceleration, efficient batching, and model pruning.
- Ethical AI and Bias Mitigation: Proactive strategies to identify and reduce biases in LLM outputs, alongside robust mechanisms for ensuring fairness and transparency.
- Data Privacy for Sensitive Prompts: Implementing strict controls and anonymization techniques for user prompts that may contain sensitive personal or proprietary information.
- Dynamic Resource Scaling: Architecting infrastructure that can rapidly scale compute resources up or down to handle fluctuating LLM inference loads.
Synergies and Shared Foundational Elements
It's crucial to recognize that LLMOps does not replace MLOps but rather extends and specializes its core principles. Many foundational elements remain vital, forming the bedrock upon which LLM-specific functionalities are built:
- Infrastructure Provisioning: Tools like Terraform or Kubernetes for managing underlying compute resources are shared.
- CI/CD Principles: The automation of testing, building, and deploying code remains essential, though artifacts might shift from trained models to fine-tuned adapters or prompt definitions.
- Data Management Practices: While the type of data differs (e.g., prompts, vector embeddings vs. tabular features), the need for data versioning, quality checks, and secure storage persists.
- Core Monitoring Concepts: Basic system health, resource utilization, and error logging are universal, though LLMOps adds layers of semantic and ethical monitoring.
In essence, LLMOps is MLOps 2.0, where the established paradigms of operationalizing machine learning are adapted and enhanced to navigate the complexities, scale, and unique challenges posed by large language models. Technical practitioners must understand both to architect truly resilient and effective AI systems.
Practical Content
MLOps: Building Robust and Reproducible ML Pipelines
Implementing successful MLOps goes beyond merely deploying a model; it's about establishing a resilient, scalable, and reproducible pipeline that can adapt to changing data and business needs. Adopting MLOps best practices ensures that your machine learning models deliver consistent value and maintain high performance in production.
- CI/CD for ML: Embrace continuous integration and continuous deployment principles. This involves automated testing of code, data pipelines, and models, followed by streamlined deployment processes. Tools like Jenkins, GitLab CI/CD, and specialized platforms like Kubeflow facilitate automated builds, tests, and deployments of your ML components.
- Robust Data Versioning: Just as critical as code versioning, robust data versioning allows you to track changes in datasets, revert to previous versions, and ensure model reproducibility. Tools like DVC (Data Version Control) integrate well with Git to manage data and model artifacts.
- Experiment Tracking: Systematically log every experiment, including code versions, hyperparameters, metrics, and data used. Platforms like MLflow or Weights & Biases are indispensable for managing the entire ML lifecycle, offering clear visibility into model development.
- Automated Model Testing: Implement comprehensive test suites for your models. This includes unit tests for feature engineering logic, integration tests for pipeline components, performance tests (latency, throughput), and crucial data quality checks to prevent training on corrupted or inconsistent data.
- Continuous Monitoring & Alerting: Deploy monitoring solutions to track model performance (accuracy, precision, recall), data drift (changes in input distribution), and concept drift (changes in the relationship between input and target variables). Set up alerts to notify teams of significant deviations, enabling proactive intervention.
- Infrastructure-as-Code (IaC): Define and provision your ML infrastructure using code (e.g., Terraform, CloudFormation). This ensures consistent environments across development, staging, and production, minimizing configuration errors and accelerating deployment.
LLMOps: Navigating the Nuances of Large Language Models
While sharing foundational similarities with MLOps, LLMOps implementation introduces unique challenges and opportunities specific to large language models. The focus shifts towards managing the iterative nature of prompt engineering, ensuring model safety, and optimizing inference costs.
- Prompt Versioning and Lifecycle Management: Prompts are the new code. Establish a system for prompt versioning, tracking changes, and linking specific prompts to model versions and evaluations. Platforms like LangChain or custom solutions can help manage prompt templates, few-shot examples, and their evolution over time.
- Managing LLM Drift: LLMs are susceptible to various forms of drift. Beyond traditional data and concept drift, prompt drift (when subtle changes in input prompts alter model behavior) and behavioral drift (changes in the underlying LLM itself or its fine-tuning) require constant vigilance. A/B testing for prompts and continuous evaluation are crucial.
- A/B Testing for Prompts: Experiment with different prompt strategies (e.g., chain-of-thought, persona-based) in a controlled environment to determine their impact on performance, accuracy, and user experience. This empirical approach is key to optimizing LLM interactions.
- Building Ethical Guardrails and Model Governance: Given the generative nature of LLMs, robust ethical AI practices are paramount. Implement content filters, toxicity detection, and bias mitigation strategies. Establishing clear model governance rules helps prevent the generation of harmful, biased, or misleading content, ensuring responsible AI deployment.
- LLM Cost Optimization Strategies: LLM inference and fine-tuning can be costly. Strategies include intelligent model selection (using smaller, cheaper models for simpler tasks), caching frequently requested prompts and responses, batching requests, and optimizing token usage through efficient prompt engineering. Focusing on LLM cost optimization is critical for sustainable deployment.
Essential Tools and Collaborative Dynamics
The right tools are accelerators for MLOps and LLMOps, fostering collaboration and streamlining workflows.
- Key MLOps Tools: For traditional ML, popular choices include MLflow for experiment tracking and model registry, Kubeflow for orchestrating ML workflows on Kubernetes, and cloud-native solutions like Amazon SageMaker, Google Cloud AI Platform, and Azure Machine Learning.
- Key LLMOps Tools: For LLM-specific operations, frameworks like LangChain and LlamaIndex provide robust abstractions for building LLM applications. Tools like Weights & Biases can track prompt variations and LLM evaluations, while specialized LLM platforms (e.g., OpenAI API, Anthropic API, Hugging Face Inference Endpoints) offer managed model access and deployment.
Ultimately, both MLOps and LLMOps are about fostering seamless team collaboration. They bridge the gap between data scientists (who develop models/prompts), ML engineers (who build and maintain pipelines), and product teams (who define requirements and evaluate impact). By establishing shared tooling, clear processes, and robust monitoring, organizations can ensure that AI/ML models, whether traditional or large language models, deliver reliable, ethical, and valuable outcomes consistently.
"Effective MLOps and LLMOps aren't just about technology; they're about culture – a commitment to continuous improvement, collaboration, and responsible AI deployment."
Comparison/Analysis
Understanding the fundamental distinctions between MLOps and LLMOps is paramount for any organization navigating the modern AI landscape. While both disciplines aim to streamline the lifecycle of machine learning models, their methodologies, challenges, and optimal application scenarios diverge significantly due to the inherent nature of the models they manage. This section provides a clear LLMOps vs MLOps comparison, highlighting their key differences and guiding you towards informed decisions.
MLOps vs. LLMOps: A Side-by-Side Analysis
To truly grasp the operational paradigm shift, let's examine a direct comparison across critical dimensions:
| Dimension | MLOps (Traditional ML) | LLMOps (Large Language Models) |
|---|---|---|
| Data Handling | Primarily structured, labeled data. Focus on feature engineering, data pipelines, and managing training/serving skew for specific tasks. Data scales are typically smaller to medium. | Vast amounts of unstructured text/multimodal data for pre-training. Fine-tuning with smaller, task-specific datasets. Emphasis on data curation, prompt engineering, and RAG data sources. |
| Model Types | Discriminative models (e.g., classification, regression, object detection). Task-specific, smaller models trained from scratch or fine-tuned on modest datasets. | Generative models (Large Language Models, Foundation Models). Pre-trained on massive corpora, then adapted via fine-tuning, prompt engineering, or RAG. High parameter counts. |
| Model Evaluation | Quantitative metrics (accuracy, precision, recall, F1-score, RMSE, AUC). Clear ground truth, automated testing, A/B testing. Focus on statistical performance. | Blends quantitative (e.g., perplexity for fluency, ROUGE for summarization) with extensive qualitative and subjective human feedback. Crucial focus on safety, bias, relevance, coherence, and usefulness. Prompt-based evaluation. |
| Iteration Cycles | Feature-centric and model-centric iterations. Retraining models with new data or improved architectures. | Prompt-centric and fine-tuning iterations. Experimenting with different prompts, RAG strategies, or smaller-scale fine-tuning. Guardrail and safety mechanism iterations. |
| Deployment & Serving | Model packaging, API endpoints, containerization, scalable inference, shadow deployment, canary releases. Simpler API schemas. | High-throughput, low-latency inference for massive models. Prompt management, guardrail integration, tokenization, contextual window management. More complex API interactions. |
| Governance & Ethics | Data privacy, fairness, explainability (XAI), bias detection in training data and model outputs. Data governance is often well-defined. | Beyond traditional concerns: managing hallucinations, preventing misinformation, toxicity detection, intellectual property concerns, alignment with human values, and emergent bias. Requires sophisticated ethical oversight. |
Navigating the Unique Challenges of Large Language Models
While MLOps has matured to address common MLOps challenges like data drift, model decay, and feature store management, LLMs introduce a new frontier of complexity. The LLMOps unique challenges stem from the very nature of these models: their immense size, emergent behaviors, and the open-ended nature of their outputs.
- Hallucinations: LLMs can generate factually incorrect yet highly convincing information. Mitigating this requires sophisticated retrieval-augmented generation (RAG) techniques, robust fact-checking, and continuous human validation in the model evaluation process.
- Bias Amplification: Trained on vast swaths of internet data, LLMs can inadvertently learn and perpetuate societal biases, leading to unfair or discriminatory outputs. Detecting and mitigating these biases is an ongoing and complex task.
- Emergent Behaviors: LLMs can exhibit unpredictable behaviors or capabilities not explicitly programmed, making consistent performance and safety guarantees particularly difficult.
- Cost and Compute: The sheer computational expense of training and inferencing LLMs necessitates specialized infrastructure and optimization strategies.
- Prompt Engineering Dependency: The quality of an LLM's output is heavily reliant on the input prompt, turning prompt engineering into a critical skill and a central part of the iteration cycle.
Strategic Application: MLOps, LLMOps, and the Hybrid Imperative
Deciding when to employ MLOps, LLMOps, or a combination thereof hinges on your project's specific requirements, data characteristics, and desired outcomes. This forms a crucial decision framework for AI architects and engineers.
When to Use MLOps:
Traditional MLOps remains the gold standard for projects involving:
- Well-defined Tasks: Predictive analytics, classification, regression, recommendation systems, traditional computer vision (e.g., object detection, image classification).
- Structured Data: Tabular data, time series, clearly labeled datasets.
- Clear, Quantifiable Metrics: Scenarios where performance can be objectively measured with metrics like accuracy, F1-score, or RMSE.
- Resource Constraints: When operational costs and computational resources are a significant concern, as traditional ML models are often less resource-intensive than LLMs.
- Examples: Fraud detection, customer churn prediction, inventory forecasting, spam classification.
When to Use LLMOps:
LLMOps becomes essential for projects leveraging the power of generative AI and complex language understanding:
- Generative Tasks: Content creation (articles, marketing copy), code generation, creative writing.
- Complex Language Understanding: Advanced summarization, nuanced Q&A systems, virtual assistants, chatbots requiring human-like conversational abilities.
- Dynamic User Interactions: Applications where the system needs to respond flexibly and contextually to open-ended user inputs.
- Unstructured Text Data: When the primary input and output are free-form text, and the value lies in semantic understanding and generation.
- Examples: AI customer support agents, personalized content generation platforms, intelligent document analysis, coding assistants.
The Hybrid Approach: The Future of AI Systems
Increasingly, the most advanced AI solutions are adopting a hybrid MLOps strategy, combining the strengths of both paradigms. Consider an intelligent assistant that first uses a traditional ML model (MLOps) to classify user intent (e.g., "order status," "technical support"). If the intent is complex or requires generative capabilities, it then routes the request to an LLM (LLMOps) for a nuanced, human-like response. This approach allows organizations to leverage the robustness and efficiency of traditional ML for specific, well-defined sub-problems while harnessing the generative power and flexibility of LLMs for more open-ended or creative tasks.
A truly holistic AI pipeline will integrate components from both MLOps and LLMOps, ensuring seamless orchestration, consistent monitoring, and robust governance across the entire lifecycle of a complex AI system. This integration is not just beneficial; it is becoming critical for building scalable, reliable, and ethically responsible next-generation AI applications.
Conclusion
The Evolving Landscape of AI Operations
Throughout this exploration, we've dissected the crucial distinctions between MLOps and LLMOps, clarifying their unique requirements and overlapping principles. While MLOps provides a robust, proven framework for traditional machine learning models, emphasizing reproducibility, scalability, and lifecycle management, LLMOps emerges as a specialized discipline tailored to the unique complexities of large language models. This includes navigating the nuances of prompt engineering, managing massive training data, ensuring model safety and fairness, addressing high inference costs, and implementing sophisticated evaluation strategies often involving human feedback. Crucially, both methodologies share the overarching goal: to reliably and responsibly bring AI models from development to production and maintain them effectively at scale. The choice isn't about one replacing the other, but rather understanding when and how to apply the appropriate operational rigor.Navigating the Future with Strategic AI Operations
The field of AI is characterized by relentless innovation, and the operational paradigms supporting it are no exception. The **MLOps future** will undoubtedly see further automation and integration, while **LLMOps trends** point towards more sophisticated fine-tuning techniques, advanced RAG implementations, and enhanced mechanisms for ethical deployment and model interpretability. We anticipate a convergence where general MLOps principles provide the foundational layer, with LLMOps contributing specialized tools and practices for generative AI. Effective **AI governance** will become paramount, necessitating transparent processes for model monitoring, bias detection, and compliance across all AI deployments. Organizations must cultivate a culture of **continuous improvement**, adapting their operational strategies as new models and technologies emerge to stay competitive and responsible.Your Next Steps in AI Deployment
As you navigate the exciting yet challenging world of AI, understanding the nuances between MLOps and LLMOps is no longer optional—it's foundational. We encourage you to evaluate your organization's current **AI strategy** and operational maturity. For those embarking on generative AI projects, integrating robust LLMOps principles from the outset will be critical for success, mitigating risks, and accelerating time to value. Consider:- Assessing your existing MLOps pipeline for adaptability to LLM specific challenges.
- Investing in specialized tooling and expertise for prompt management, safety alignment, and LLM evaluation.
- Fostering collaboration between data scientists, ML engineers, and policy experts to ensure responsible AI practices.


Comments (0)
Please login or register to leave a comment.
No comments yet. Be the first to comment!